
滤波类状态估计方法
滤波类状态估计方法
1. 前言
1.1 现实中位置描述
在生活中,我们经常需要描述位置信息。回顾我们的日常习惯,我们通常使用两种方法来描述位置:
- 一种是使用定位软件,如百度地图、卫星定位系统、甚至古代的指南针等等,它们会给我们一个精确信息,告知我们身处何处,距离目标有多少米,将位置精确为一个点。
- 然而,通常当我们向他人描述位置的时候,我们很少借助定位,而是会描述目标的粗略方位(如东西南北等),和我们的距离(大概二三百米),这样目标的位置则不是一个精确的点,而是一个环形的区域目标可能在这个区域任何一个地方出现,也就说位置信息变成了一个等可能概率模型。这便是概率状态估计的现实意义。
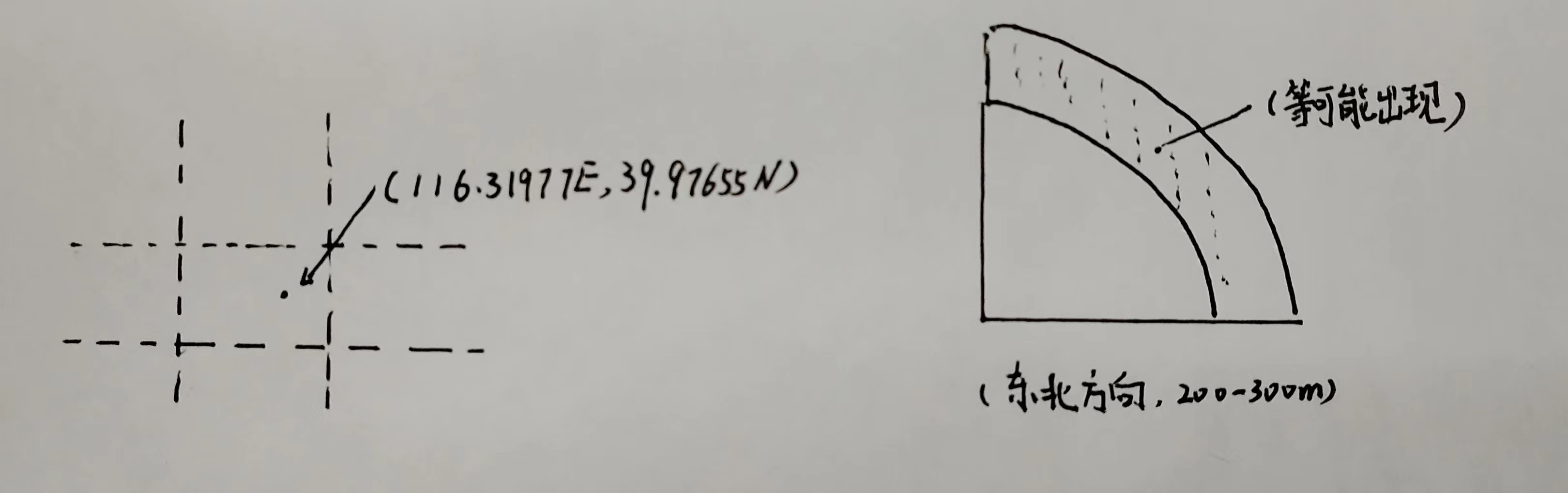
1.2 概率状态估计
很多时候,我们描述一个物体的时候,它其实并不是物理意义上的一个质点,是一个有体积的实物,也就说质点是物体一个抽象,它将物体信息集中到一个点中。相反,我们也可以将这个点进行放大,那么其实这个物体只是说在这个点附近出现的可能性最高,它的信息分散在概率之中。
类似二维高斯分布和热力图,在点附近的概率和热力度最高,离点越远概率和热力越低。同时,当我们对位置描述的越精准,高斯分布的方差也就越小,变得更加集中,热力图的热量则更会集中在一个区域,其他区域热度更小。
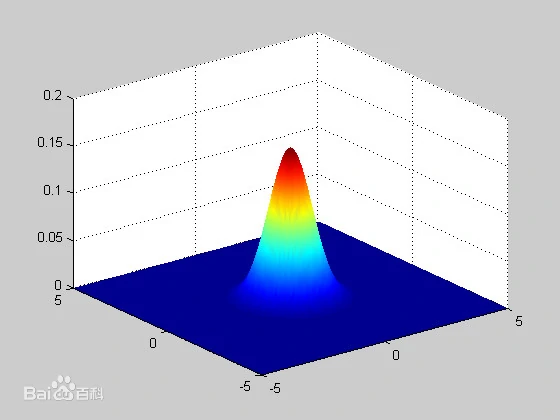
这样其实所有的位置或是状态,就可以使用概率模型来进行描述,那么我们对位置或状态的估计就变成了对概率的估计。
2. 概率知识
- 我们将简要介绍一些基础的概率知识。
- 熟悉的读者可以跳过这一部分
2.1 离散概率分布
- X 是一个随机变量
- X 取值在一个可数的集合之中$\{x_1,x_2,…,x_n\}$
- $P(X=X_i)orP(X_i)$则表示X取$X_i$的概率
- $P(\cdot)$ 则表示概率质量函数,即其所有可能的概率取值
2.2 连续概率分布
- X 是一个连续变量
- $P(X=x),or P(x)$,表示概率密度函数
2.3 条件概率
- 设A,B为两个事件且$P(A)>0$,则$P(B|A)=\frac{P(AB)}{P(A)}$,为事件A发生下事件B发生的条件概率
- 根据这个我们有 $P(AB)=P(B|A)*P(A)$
2.4 概率和
- 全概率和 $\sum_{x}P(x) = 1, \int P(x)dx=1$
- 偏概率和 $P(x)=\sum_yP(x,y),\int_yP(x,y) = P(x)$
- 条件概率 $P(x) = \sum_yP(x|y)P(y), \int_yP(x|y)P(y)$
- 条件概率推广 $P(x|y)=\sum_zP(x|z,y)P(z|y),P(x|y)=\int_zP(x|z,y)P(z|y)dz$
2.5 Bayes公式
- 公式的直观理解:造成结果的原因 = 结果*先验知识/所有结果
- Bayes公式给我们一个方式,让我们根据现有的观测结果和先验知识去推算造成这种可能的原因,也就说根据我们的观测计算目标状态和位置
2.6 高斯分布
- $\mu$ 为均值,$\sigma^2$ 为方差的高斯分布
3. 概率状态估计
3.1 相关概念
状态估计是感知问题(perception)的关键,运动则是根据观测结果所做出的的决定
- Perception = state estimation
- Action = optimization
传感器是有噪声的,环境也是动态的,感知是很难得到保证的,而感知中的概率模型,可以通过调整方差量来表示噪声项
3.2 估计方法
根据我们以上的介绍,在我们有观测结果(perception)的情况下,如果想知道物体的具体状态,我们需要计算:
根据Bayes公式有:
观测Bayes公式,我们发现我们只需要知道$p(per|st)和p(st)$即可,一般来说
- $p(per|st)$ 为传感器给定的常识概率分布
- $p(st)$ 则是根据我们已知情况给出的先验知识
由此,我们便可以估计当前状态
3.3 举例
我们拿一个开关门的例子演示一下具体流程
现在,我们使用传感器观测门的状态
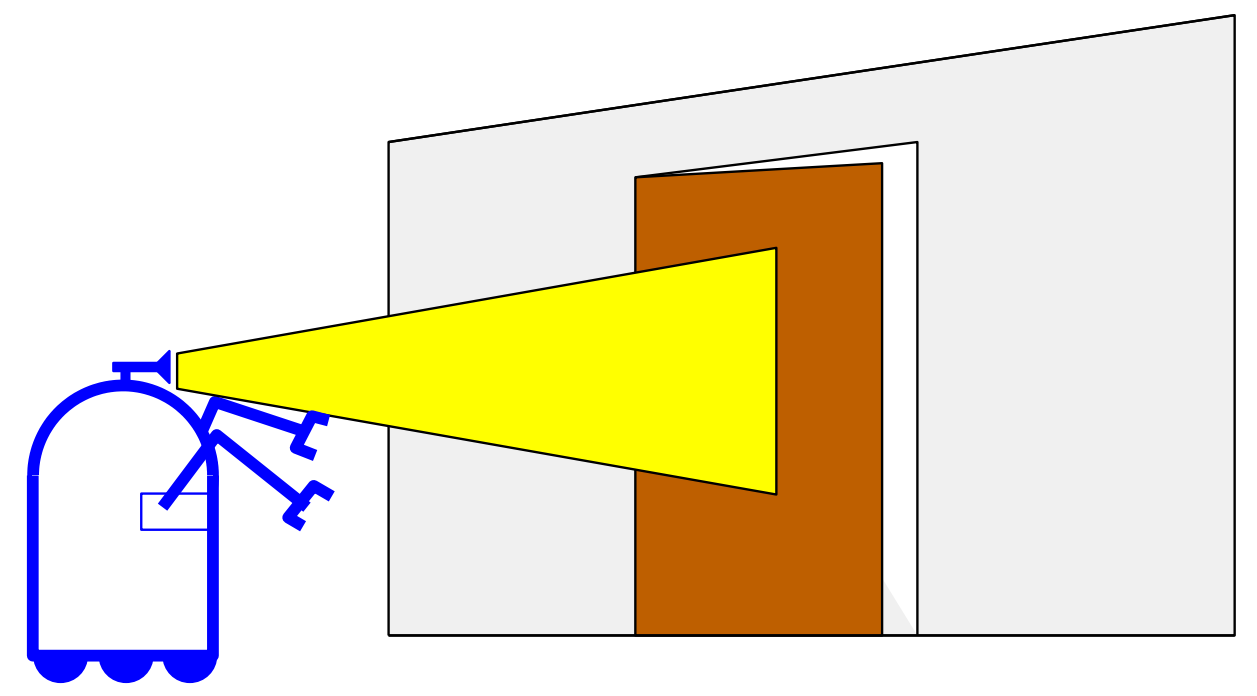
- 门只有可能有两种状态开或关,我们一开始也不知道门的状态,那么我们就可以假设为$p(open) = 0.5,p(close)=0.5$,即其开关是等可能的
- 而我们传感器的概率分布如下
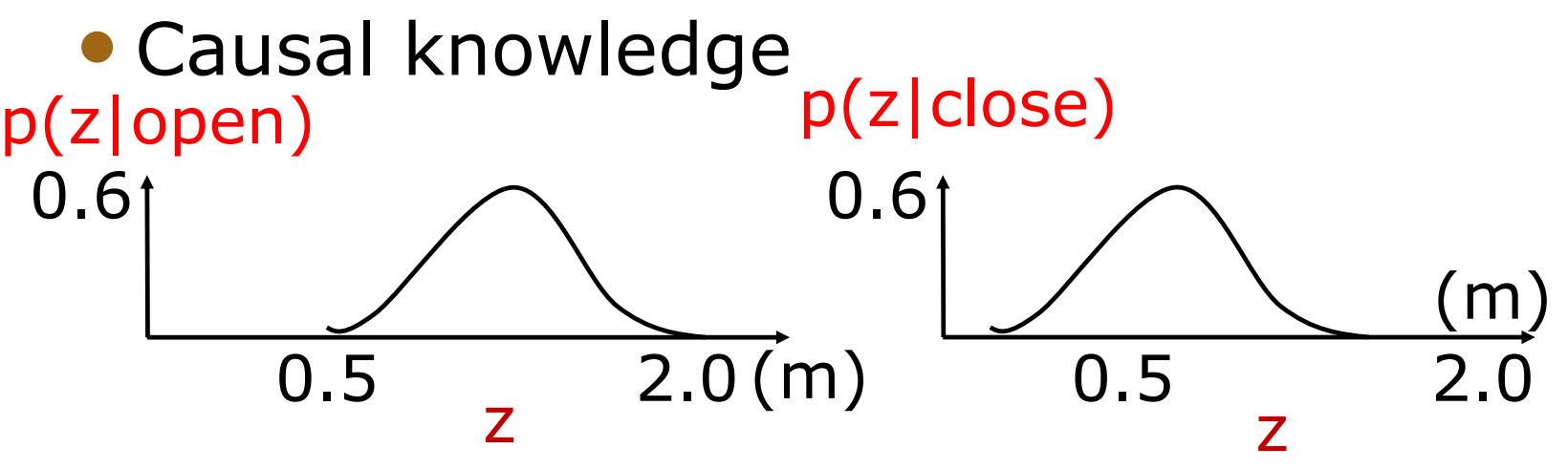
那么通过Bayes公式有
如果我们的观测结果 z=1.5,那么 $p(z|open)=0.6, p(z|close)=0.3$
代入我们已有的结果
3.4 多观测条件下Bayes推广
通过例子,我们很容易看出在有观测的情况下,我们对门状态的认知有了明显的提升。那么,当我们有更多观测的时候,我们的认知也会进一步提升。
那么如果我们有观测$z_1,z_2$,我们需要计算
如果我们有更多的观测,对公式进一步推广
这样的推广会出现问题,我们无法得到 $p(z_n|x,z_1,…,z_{n-1})$概率模型
然而,在实际情况中,每个观测其实是独立的,也就是说我们可以利用Markov假设
这样,我们把观测模型进行了统一
考虑我们之前的例子,有其他观测结果$p(z_2|open)=0.6,p(z_2|close)=0.3$
代入我们公式
3.5 运动模型
运动是根据观测所做出的决定,而因为运动不是完全确定的,会增加状态的不确定性。通俗的讲,我们执行一个操作,其带来的结果是不确定的。
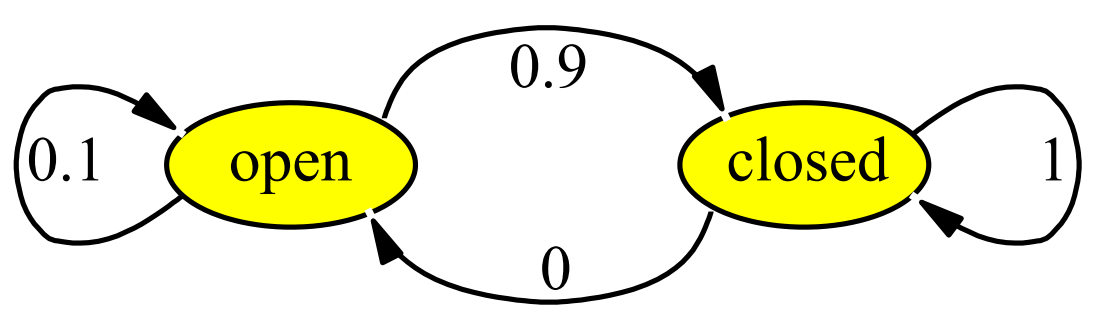
如,我们执行一个关门的操作,在门开着的情况下,有0.9可能关门,也有0.1没有关上门。
对此,我们引入运动的表达
u代表执行u使得$x’$转换到$x$状态
因此我们对状态转移的计算如下:
- $P(x|u)=\int P(x|u,x’)P(x’)dx’$
- $P(x|u)=\sum P(x|u,x’)P(x’)$
回到我们的例子,如果我们执行一个关门操作 u
4. Bayes 滤波
有了上述的概率状态估计方法,我们以此使用观测和运动进行更新状态即可,那么Bayes滤波方法也就呼之欲出了。
我们有
- 我们有一组观测和运动 $d_t=\{u_1,z_1,…,u_t,z_t\}$
- 观测模型 $P(z|x)$
- 运动模型 $P(x|u,x’)$
- 初始的先验状态 $P(x)$
想知道
- 状态概率 $Bel(x_t)=P(x_t|u_1,z_1,…,u_t,z_t)$
和之前类似,我们也采用Markov假设
- 运动后预测状态 $p(z_t | x_{t-1}, u_t )$
- 观测后估计状态 $p(z_t|x)$
由此,我们得出Bayes滤波的基本公式
- 运动后预测状态 $\begin{aligned}\overline{bel}(x_t) = \int p(x_t|u_t,x_{t-1})bel(x_{t-1})dx_{t-1}\end{aligned}$
- 观测后估计状态 $bel(x_t) = \eta p(z_t|x_t)\overline{bel}(x_t)$
进一步,当我们的观测为多个时,假设其相互独立
同样的,当我们状态转移也有多种时,状态转移图就就无法统一的进行描述,因此我们使用状态转移矩阵的方式。如图所示,对于四种运动我们有四个状态转移矩阵,矩阵中的元素代表在此操作下,两个状态转移的概率。

5. Kalman 滤波
从Bayes滤波我们可以看出,其核心在于得到传感器的概率分布,然而有时候传感器的概率分布我们无从得知,或者无法用确定的函数表示,那么这个时候我们应该如何做呢?从我们日常经验来看,一般这个时候我们都会去寻求近似,那么如何利用已知的情况去近似呢?
我们不免想起我们的概率中老朋友高斯分布,当我们使用高斯分布去作为我们传感器的概率分布时,我们就得到了Kalman 滤波。
我们有
- $p(x)\thicksim N(\mu,\sigma^2)\thicksim N(\mu,\Sigma)$
- 因为高斯分布的运算封闭,因此我们只需要运算高斯分布的均值和方差即可
那么
- $p(x_t|u_t,x_{t-1})\Rightarrow {x_t=A_tx_{t-1}+B_tu_t+\mathcal{E}_t}$
- $\mu=A_{t}x_{t-1}+B_{t}u_{t}$
- $\varepsilon_t\sim N(0,\sigma_{\varepsilon_t}^2)$
- $p(z_t|x_t)\Rightarrow \begin{aligned}z_t=H_tx_t+\delta_t\end{aligned}$
- $\mu=H_{t}x_{t}$
- $\delta_t\sim N(0,\sigma_{\delta_t}^2)$
其中
- $A_t$ 状态转移矩阵:没有控制和噪声的情况下的状态转移矩阵 nn*
- $B_t$ 输入矩阵:描述 $\mu_t$ *如何影响状态变化 nl
- $H_t$ 观测矩阵:kn*,$z_t$和$x_t$之间的关系
- $\varepsilon_t$ 过程噪声:其方差矩阵为 $R_t$ *,nn
- $\delta_t$ 观测噪声:其方差矩阵为 $Q_t$,kk*
得到Kalman 滤波的方法
- 运动预测
- 基于转移和控制预测 $\overline{\mu}_t=A_t\mu_{t-1}+B_tu_t$
- 预测方差 $\overline{P}_t=A_tP_{t-1}A_t^T+R_t$
- 观测修正
- Kalman 增益 $K_t=\overline{P}_tH_t^T(H_t\overline{P}_tH_t^T+Q_t)^{-1}$
- 状态更新 $\mu_t=\overline{\mu}_t+K_t\boxed{(z_t-H_t\overline{\mu}_t)}(Innovation \ provided\ by\ z_t)$
- 方差更新 $P_t=(I-K_tH_t)\overline{P_t}$
6. 扩展Kalman 滤波(EKF)
我们从Kalman 滤波的公式中可以发现,其中包含着很强的线性假设,其对于线性系统的滤波是最优的。但是,绝多数现实中的系统都不是线性的,那么我们应该如何去近似呢?
有非线性到线性的转换,我们最熟悉的莫过于泰勒公式了,利用泰勒公式的一阶近似,我们就得到了EKF的基本原理。
- 转移
- 观测
得到EKF 方法
- 预测
- $ \mu_{t}=g(u_t,\mu_{t-1})$
- $ \overline{P}_t=G_tP_{t-1}G_t^T+R_t$
- 修正
- $K_t=\overline{P}_tH_t^T(H_t\overline{P}_tH_t^T+Q_t)^{-1}$
- $\mu_{t}=\overline{\mu}_{t}+K_{t}(z_{t}-h(\overline{\mu}_{t}))$
- $P_{t}=(I-K_{t}H_{t})\overline{P}_{t}$
- 其中
- $H_t=\frac{\partial h(\overline{\mu}_t)}{\partial x_t}\quad$
- $G_t=\frac{\partial g(u_t,\mu_{t-1})}{\partial x_{t-1}}$
7. 无迹卡尔曼滤波(UKF)
和之前一样,在考虑EKF 时我们也会问一阶近似是否足够,如果不够那么我们应该怎么办?
考虑概率论的方法,一个曲线的除了由它本身、导数所描述,也有其构成点所描述,那么我们只需要进行特定的采样,就可以对系统状态的概率分布进行近似,这就是UKF。
UKF的算法包括以下几个步骤:
- 选择Sigma点:根据系统状态的均值和协方差矩阵,使用无迹变换的方法选择一组Sigma点。这些Sigma点包括系统状态的均值点和由均值和协方差矩阵计算得到的一些偏差点。
- 预测步骤:对每个Sigma点进行系统状态的预测。通过应用系统动态模型,将每个Sigma点转换为预测状态。
- 估计预测均值和协方差:根据预测的Sigma点,计算预测状态的均值和协方差。这些预测值将用作测量更新步骤的先验估计。
- 测量更新步骤:对每个预测状态进行测量更新。通过应用测量模型,将每个预测状态转换为测量空间中的估计值。
- 估计测量均值和协方差:根据测量更新的估计值,计算测量状态的均值和协方差。
- 计算卡尔曼增益:使用预测和测量的均值和协方差,计算卡尔曼增益,用于融合预测和测量的信息。
- 更新状态估计:根据卡尔曼增益,将预测状态和测量状态进行加权融合,得到最终的系统状态估计。
UKF的具体计算方法比较复杂,感兴趣的读者可以自行查阅。
8. 粒子滤波
粒子滤波(Particle Filter)是一种基于蒙特卡洛方法的概率状态估计技术,用于非线性和非高斯系统的状态估计。粒子滤波通过使用一组粒子来逼近系统状态的后验概率分布,并根据系统动态模型和测量信息进行更新。
粒子滤波的基本思想是通过在状态空间中随机采样一组粒子,每个粒子表示系统可能的状态。这些粒子的权重根据预测模型和测量模型进行更新,从而反映了它们与实际状态的拟合程度。在每个时间步骤中,粒子滤波通过对粒子进行重采样和更新,逐渐逼近系统的后验概率分布。
下面是粒子滤波的详细步骤:
- 初始化:根据先验知识或初始测量值,生成一组随机的粒子,并为每个粒子分配相同的权重。
- 预测步骤:通过应用系统动态模型,对每个粒子进行状态的预测。可以通过从先前状态中采样,并根据系统动态模型添加随机噪声来实现。
- 权重更新:根据测量模型,计算每个粒子的权重。权重表示了粒子与实际测量值的拟合程度。拟合程度较好的粒子将获得较高的权重,而拟合程度较差的粒子将获得较低的权重。
- 标准化权重:对所有粒子的权重进行标准化,使它们之和等于1。这样确保了权重表示概率分布。
- 重采样:根据粒子的权重,进行重采样操作。较高权重的粒子将以较高的概率被选中,而较低权重的粒子将以较低的概率被选中。通过重采样操作,粒子集合中的粒子数目会趋于稳定,以更好地表示后验概率分布。
- 状态估计:根据重采样后的粒子集合,可以通过计算粒子的加权平均值或加权中位数来获得对系统状态的估计。
重复执行上述步骤,粒子滤波可以逐步逼近系统的后验概率分布,并提供对系统状态的估计。
感兴趣的读者可以继续深入了解。
9. 总结
本文,从日常生活的经验出发,尝试梳理滤波类方法的发展过程。滤波类状态估计方法包括Kalman滤波、扩展Kalman滤波(EKF)、无迹卡尔曼滤波(UKF)和粒子滤波。这些方法都是用于非线性系统状态估计的重要工具,主要详细介绍了Kalman 滤波和扩展Kalman滤波(EKF)。
首先是Kalman滤波,它是一种基于高斯分布的状态估计方法。Kalman滤波使用线性模型和高斯分布来近似系统的状态和测量噪声。它通过运动预测和观测修正两个步骤来更新状态估计和方差估计。
接下来是扩展Kalman滤波(EKF),它是对Kalman滤波的非线性扩展。EKF使用泰勒公式对非线性系统进行线性近似,从而使得Kalman滤波方法也适用于非线性系统。通过对状态转移和观测模型进行线性化,EKF能够在非线性系统中进行状态估计。
然后是无迹卡尔曼滤波(UKF),它是对EKF的改进。UKF使用无迹变换的方法选择一组Sigma点来近似系统状态的分布。通过对这些Sigma点进行预测和测量更新,UKF能够更准确地估计非线性系统的状态。
最后是粒子滤波,它是一种基于蒙特卡洛方法的概率状态估计技术。粒子滤波通过使用一组粒子来逼近系统状态的后验概率分布,并根据系统动态模型和测量信息进行更新。通过对粒子的重采样和更新,粒子滤波能够逐步逼近系统的后验概率分布,提供对系统状态的估计。
总而言之,这些滤波类状态估计方法在非线性和非高斯系统的状态估计中发挥重要作用。它们通过不同的近似和采样方法,能够有效地对系统状态进行估计,并提供准确的预测和修正。这些方法在估计和控制领域有广泛的应用,可以用于机器人导航、目标跟踪、信号处理等多个领域。
